
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Nintendo
- NetVLAD
- 장소인식
- PointNet
- SFC30
- AveragePrecision
- identification
- pointcloud
- 엘리트패드
- deeplearning
- 패미컴
- CNN
- 이미지탐색
- nintendo switch
- FasterRCNN
- 닌텐도
- 딥러닝
- rcnn
- 현대컴보이
- CVPR
- XBOX ONE PAD
- descriptor
- RPN
- Cuboid Detection
- 8bitdo
- 700D
- ELITE PAD
- Reidentification
- XBOX ONE
- DeepFeature
- Today
- Total
HAYEUP
Bag of Tricks and A Strong Baseline for Deep Person Re-Identification 본문
논문 제목은 Bag of Tricks and A Strong Baseline for Deep Person Re-identification 으로 CVPR 2019 논문입니다.
Person Tracking Problem에서 Person Re-identification을 수행하기 위한 딥러닝 모델과 해당 모델을 학습하는데 유용한 방법, 트릭을 소개합니다.
논문의 어감을 최대한 전달하기 위해 특정 단어는 영어 그대로 적었습니다.
Abstract
본 논문에서는 간단하고 효율적인 Baseline Model과 유용한 Tricks를 소개합니다. 이러한 방법을 통해 Market1501 Dataset 기준으로 Global Feature만을 사용해 94.5% rank-1 Accuracy와 89.5% mAP를 달성합니다.
Introduction
비교를 위해 ECCV2018과 CVPR2018에 소개되었던 논문들을 조사했고 다른 모든 방법들보다 월등한 성능을 보여줍니다.


논문의 목표는 다음과 같습니다
- 최고 컨퍼런스의 Method들이 빈약한 Baseline에서 확장된것을 조사
- 연구자들에게 학술적인 기여를 위해 person ReID의 강력한 Baseline을 제공
- 어떤 Trick이 ReID 모델의 성능에 영향을 미치는가에 대한 Reference를 제공
- 산업계에 기여를 위해 복잡한 Consumption 없이 성능을 높일수 있는 효과적인 Trick 제공
논문의 Contribution은 다음과 같습니다.
- person ReID를 위한 효과적은 Trick들을 조사하고 BNNeck이라는 새로운 Structure를 디자인하고 각각의 Trick의 개선성능을 시험합니다.
- ResNet50을 Backbone으로 디자인한 BNNeck 모델은 global feature를 이용한 person ReID에서 최고의 성능을 보입니다.
- Image 크기와 Batch 크기가 성능에 미치는 영향을 시험합니다
Standard Baseline
Baseline은 ResNet50을 backbone으로 사용합니다. Training stage의 Pipeline은 다음과 같은 step으로 이루어집니다.
- ImageNet pre-trained ResNet50의 Fully Connected Layer의 dimension을 Training Dataset의 identity 개수로 변경.
- P개의 identity와 각 identity마다 K개의 Image를 무작위로 추출하여 Batch를 구성. 본 논문에서는 P=16, K=4로 설정.
- 입력 Image의 크기를 256 x 128 pixels로 변형. 10 pixels(0의 값)를 pad로 적용. 다시 256 x 128 크기로 변형.
- 각각의 Image는 50% 확률로 가로로 Flip.
- 각각의 Image는 32-bit floating point로 decode, 각 pixel값은 0에서 1사이. RGB 채널에 대해 ImageNet의 Mean과 Distribution을 사용하여 Normalize.
- 모델은 ReID features $f$와 ID prediction logits $p$를 출력.
- ReID feature $f$로 Triplet Loss를 계산. ID prediction logits $p$로 Cross Entropy Loss를 계산. Triplet Loss의 Margin $m$은 0.3으로 설정
- Optimizer는 Adam으로 설정. 초기 Learning Rate는 0.00035이고 40번째 epoch과 70번째 epoch에서 각각 1/10로 감소. 총 120 epoch 학습
Training Tricks

Warmup Learning Rate
ReID Model에서 Learning Rate는 커다란 영향을 끼칩니다. 최초 10 epoch동안 선형적으로 Learning Rate를 $3.5 \times 10^{-5}$에서 $3.5 \times 10^{-4}$까지 증가시킵니다. 40 epoch과 70 epoch에서 각각 $3.5 \times 10^{-5}$과 $ 3.5 \times 10^{-6}$으로 감소합니다. 수식과 그림으로 나타내면 다음과 같습니다.
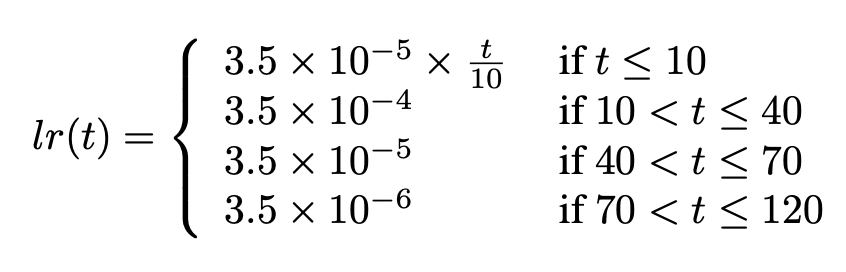
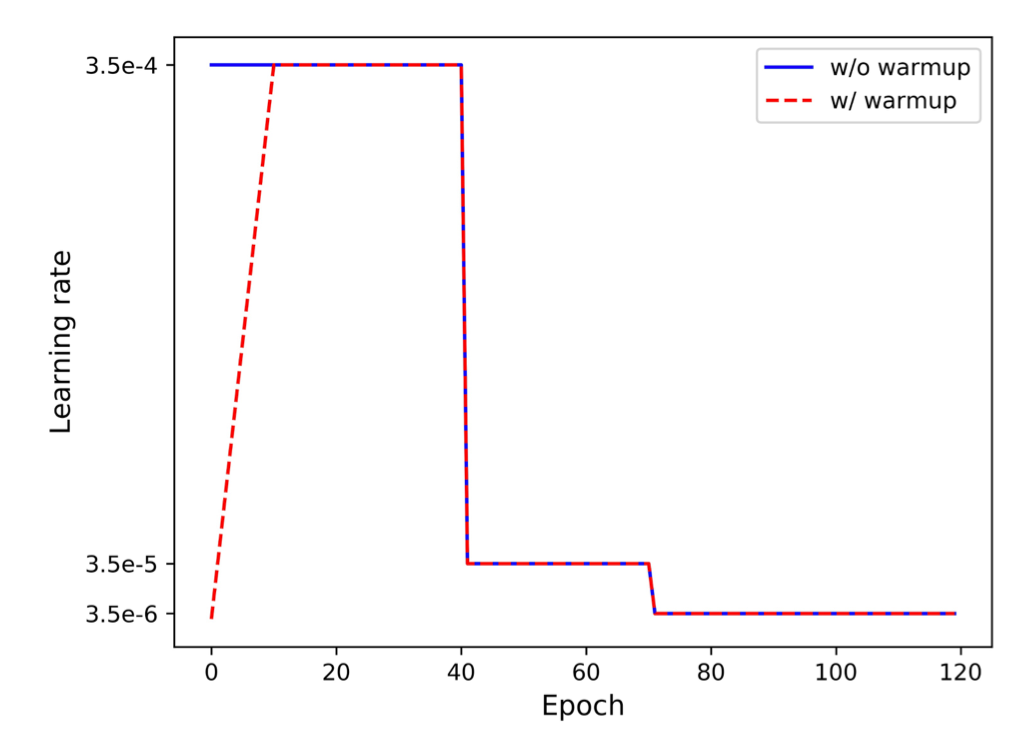
Random Erasing Augmentation
Occulutsion 문제와 Generalization 성능을 키우기 위해 Data Augmentation의 일환으로 Random Erasing Augmentation(REA)을 제안합니다. REA를 수행할 확률 $P$와 REA가 수행될 위치 $I$, REA가 수행될 크기 $S$를 특정 범위 안에서 무작위로 선정해 수행합니다.

Label Smoothing
Model의 최종 출력은 Image의 ID prediction logit으로 크기는 Dataset의 Identity Number N과 동일합니다. Image가 주어졌을 때 $y$를 truth ID, $p_{i}$를 i class의 ID prediction logits로 설정하면 Cross Entropy Loss를 다음과 같이 계산합니다.

Person ReID Task는 Test시에 Train에 참여하지 않은 Person이 포함될수 있기때문에 Model이 Person의 ID 그 자체에 Overfitting하지 않는것이 중요합니다. Label Smoothing(LS)은 많은 Classification Task에서 Overfitting을 방지하기 위해 사용됩니다. LS에 의해 위의 식의 $q_{i}$를 다음과 같이 변경합니다.

Last Stride
Spatial Resolution의 향상은 Feature의 Granularity를 증가시킵니다. 즉 Feature Map의 해상도가 높을수록 Feature Map 각각의 Pixel이 조금더 세분화된 정보를 포함합니다. ResNet50의 마지막 Stride의 크기를 2에서 1로 변경시켜 높은 해상도의 Feature Map을 획득합니다. 이 작업은 Computation을 거의 증가시키지 않으면서 성능 향상에 크게 기여합니다.
BNNeck
많은 ReID Model들이 다음 그림과 같이 학습시 Triplet Loss와 ID Loss(Cross Entropy Loss)를 같이 사용합니다.

ID Loss는 Model 학습에서 Feature가 존재하는 Hyper Space에서 Embedding Feature들을 Subspace로 나누는 Hyper Plane을 만드는 역할을 합니다. 2차원을 예로 들면 Embedding Feature들간의 거리에 상관없이 같은 ID는 같은 Space에 속하게 하는 Plane을 생성합니다. 따라서 ID Loss를 계산할때는 Euclidean Distance가 아닌 Cosine Distance를 사용합니다.

Triplet Loss는 Model학습에서 같은 ID를 갖는 Feature들간은 가깝고 다른 ID를 갖는 Feature들 간에는 거리를 멀게하는 군집을 만드는 역할을 합니다. Feature들간 직접적인 Distance계산이 필요하므로 Euclidean Distance를 사용합니다.

ID Loss와 Triplet Loss들 동시에 사용하여 다른 ID간의 구분력, 같은 ID간의 응집력을 높이는 방향으로 학습이 가능하지만 ID Loss와 Triplet Loss의 방향성 자체가 다르기때문에 하나의 Feature Output을 통해 두개의 Loss를 동시에 학습하는 것은 효율적이지 않습니다. 실제로 학습도중 한개의 Loss가 감소하는 동안 다른 Loss가 증가하는 방향으로 학습이 진행될 수 있습니다.

이러한 문제점을 해결하기 위해 BNNeck을 사용합니다. BNNeck은 Feature와 Classifier FC layer사이에 Batch Normalization Layer를 삽입하여 구성됩니다. Normalization을 거치기 때문에 Feature $f_{t}$ 와 $f_{i}$ 는 Hyper Space에서 Gaussian Distribution을 만족하는 방향으로 생성됩니다. 또한 비선형성이 추가되어 이러한 분포는 동시에 ID Loss와 Triplet Loss의 수렴을 쉽게 합니다.

BNNeck는 Classifier FC Layer의 Bias를 제거하는 Trick도 사용합니다. Bias를 제거함으로 Feature가 원점을 중심으로 Hyper Shpere위에 구성되도록 합니다. FC Layer를 Kaiming Initialization을 사용하여 Initialization 합니다.
Center Loss
Triplet Loss는 Anchor와 Positive, Negative에 의한 거리 차이에 의해 학습됩니다. Margin이 0.3일때 Anchor와 Positive의 Distance가 0.3, Negative와의 Distance가 0.5이면 Triplet Loss는 0.1입니다. 같은 방법으로 Positive 1.3, Negative 1.5이면 Triplet Loss는 0.1이 됩니다. 즉 Feature 자체의 Absolute Value가 학습에 전혀 고려되지 않습니다. 이를 해결하기 위해 Center Loss를 도입합니다.
Center Loss는 각 Class의 Feature들에 대해 Center를 학습하고 Feature와 해당 Class의 중심 사이의 거리에 패널티를 주는 방향으로 학습합니다. 식으로 나타내면 다음과 같습니다.

$f_{t_{j}}$ 는 feature, $c_{y_{j}$는 Class j의 Center를 나타냅니다. 즉 같은 Class의 Feature들이 중심으로 모이도록 학습이 진행됩니다. 따라서 Center Loss는 각 Class가 Hypersphere상에서 어디에 위치해야하는지를 학습하며 Triplet Loss의 Absolute Value가 학습에 고려되지 않는 단점을 보완합니다.
위의 Loss 3개를 합쳐 최종 Loss가 결정됩니다. Center Loss의 영향력을 낮추기 위해 Weight를 0.0005로 설정합니다.

Experimental Results
Market1501과 DukeMTMC-reID 데이터셋을 이용해서 Model을 Evaluation합니다. Rank-1 accuracy와 mAP를 Evaluation Metric으로 사용합니다. 다른 Training Setting은 수정하지 않고 Standard baseline에 Trick만 추가하여 실험합니다.

Influences of Each Trick ( Same Domain )

Trick을 하나씩 적용할 때마다 Rank-1 accuracy와 mAP 모두 증가하고 특히 BNNeck을 적용했을때 가장크게 증가합니다. 최종적으로 Market1501 Dataset에서 94.5% Rank-1 accuracy 85.9% mAP, DukeMTMC Dataset에서 86.4% Rank-1 accuracy 76.4% mAP를 달성합니다.
Analysis of BNNeck
BNNeck Architecture의 $f_{t}$와 $f_{i}$ 두개의 Feature를 비교합니다.

Feature $f_{i}$를 사용할때는 Cosine Distance가 더 좋은 성능을 보이고 Feature $f_{t}$를 사용할때는 두개의 Metric이 거의 차이가 없습니다.
Influences of Each Trick ( Cross Domain )
Training Dataset과 Evaluation Dataset을 교차시켜 성능을 시험합니다.

Learning Rate Warmup, Label Smoothing, BNNeck 방법들은 Cross Domain 환경에서 눈에띄게 성능을 향상시킵니다. REA는 오히려 성능을 떨어트렸는데 이는 REA를 사용하면 Training Dataset에 종속되는 정보들에 집중하는 학습이라고 볼 수 있습니다.
Comparison of State-of-the-Arts

각 Method들이 사용하는 Feature의 Type과 개수가 상이하기 때문에 동일한 기준으로 판단하기는 어렵습니다. Global Feature를 사용하는 Method중에서는 본 논문에서 제시한 방법이 가장 높은 성능을 보입니다.
Supplementary Experiments
학습에 사용되는 Hyperparameter들의 변경이 결과에 미치는 영향을 추가적으로 실험합니다.
Influences of the Number of Batch Size
Triplet Loss는 $ P \times K $ 개의 Image를 Batch로 사용합니다. P는 인원수 K는 인원당 Image의 개수를 나타냅니다. Triplet Loss와 Batch 크기간의 상관관계를 찾기위해 Center Loss는 제거하여 실험합니다. 결과적으로 Batch Size가 성능에 결정적인 영향을 주진 못하지만 $K$가 커지면 Batch안에 Hard Positive Pair가 포함될 확률이 높고 $P$가 커지면 Hard Negative가 포함될 확률이 높아 Batch 크기가 클수록 약간의 긍정적인 영향을 끼칩니다.

Influences of the Image Size
Image의 크기가 끼치는 영향만을 판단하기 위해 Center Loss를 제거하고 $P = 16, K = 4$로 설정하고 실헙합니다. 결과적으로 Image의 크기 또한 Batch와 마찬가지로 성능에 결정적인 영향을 끼치지 못합니다

Supplementary Experiments
본 논문은 효과적인 학습 Trick들과 Person ReID를 위한 Strong Baseline을 제공합니다. 각각의 Trick과 제시한 Method의 영향을 파악하기 위해 Same Domain과 Cross Domain 환경 모두에서 실험하였고 Global Feature만을 사용해 Market1501 Dataset기준 94.5%의 Rank-1 accuracy와 85.9%의 mAP을 달성하였습니다.
이것으로 논문 리뷰를 마칩니다. 현업이 바빠 오래만에 포스팅합니다 빠른 시일내에 또 다른 논문을 포스팅하도록 노력하겠습니다.
[참고자료]



